DR. ATABAK KH
Cloud Platform Modernization Architect specializing in transforming legacy systems into reliable, observable, and cost-efficient Cloud platforms.
Certified: Google Professional Cloud Architect, AWS Solutions Architect, MapR Cluster Administrator
From Demo to Daily: A Measurable AI Copilot Pattern on GCP
Published on 17 November 2025.
Right-Time AI: Small Copilots, Big Proof - An End-to-End PoC You Can Reproduce
In two weeks, I built three micro-copilots (reading, meeting, code) on Vertex AI served via Cloud Run, orchestrated by Workflows, and measured in BigQuery. I defined strict hypotheses (time saved, edits reduced, predictable cost), mapped decisions to right-time freshness (seconds/minutes/daily), and enforced a kill switch for reversibility. Two copilots passed (≥15% time saved, ≥20% fewer edits), one failed and was retired. In this article I would like to share some finding and the reproducible pattern, the guardrails, and the numbers - so, It will help to understand and plan to be able to decide what to keep, what to stop, and why.
Key Results:
- Reading Copilot: 17% time saved, 21% fewer edits, €0.01/task (daily batch)
- Meeting Copilot: 20% time saved, p95 latency <3 min
- Code Copilot: Mixed results - retired pending on-device experiments
- Kill Switch: 100% successful fallback rate
- Cost: Predictable €0.01-0.02 per task with no spikes
Table of Contents
- Why I Did It
- The Rules (Before Code)
- Architecture
- Implementation
- Testing Strategy
- Measurement & Metrics
- Results
- Governance & Trust
- What Failed & Why
- Reproducible Pattern
Why I Did It
Usually demos are easy, but daily impact is hard. I wanted a personal, honest answer to a simple question: Are small AI helpers to real tasks, would save people time without creating chaos or surprise costs?
The goal wasn’t to build the next ChatGPT/Gemini/Copilot or any other competitor. It was to test a repeatable, governed pattern that delivers measurable value - one that could be templated for other (personal or companies) workflows with clear success gates and a kill switch.
The Rules (Before Code)
Scope
- Three micro-copilots for workflows: reading, meetings, code
- No business data, no PII
Right-Time Freshness
- Code: seconds (interactive code review)
- Meeting: minutes (post-meeting processing)
- Reading: daily (overnight batch processing)
No fake “real-time” where decisions don’t need it.
Guardrails
- EU region only
- Plain-language prompts
- Audit logs on all operations
- One-click kill switch (
AI_ENABLED=false)
Success Gates
- H1: ≥15% time saved on ≥2 copilots (median over 5+ runs)
- H2: Edits reduced by ≥20% vs. baseline
- H3: Stable cost/task with ceilings per use case
- H4: p95 latency meets SLA for its freshness tier
- H5: Reversibility proven (kill switch -> clean fallback, logged)
Architecture
System Overview
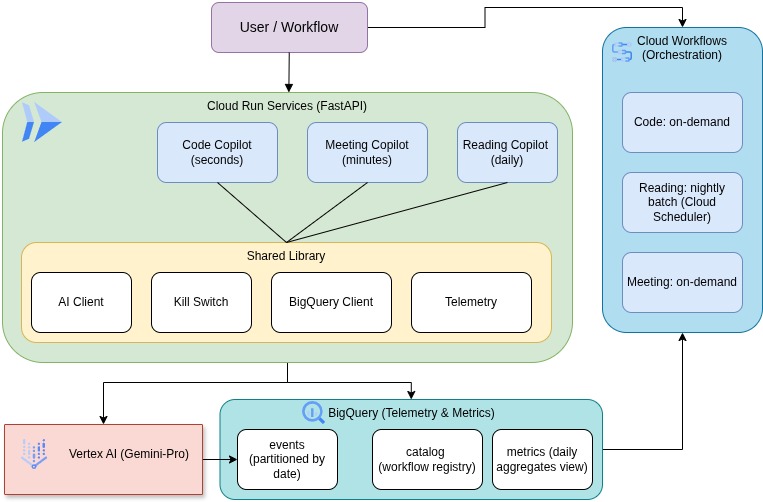
Component Details
I have used a personal gmail account with free 3 month 300 credit for this test, and the details are as below:
1. Cloud Run Services
Characteristics:
- Serverless, auto-scaling (0 to N instances)
- Request timeout: 300 seconds
- Container concurrency: 80
- CPU: 1 vCPU, Memory: 512Mi
- Cost optimization: Scale to zero, max 3 instances
Endpoints:
POST /suggest- Main copilot endpointGET /health- Health check with kill switch status
2. BigQuery Schema
Dataset: copilot_poc
Tables:
events- One row per invocation with full telemetrycatalog- Workflow registry with freshness tiers and SLAsmetrics(view) - Daily aggregates by copilot
Partitioning: Events table partitioned by date
Clustering: By copilot and outcome for query optimization
3. Security & Governance
- IAM: Service accounts with least-privilege roles
- Secrets: Secret Manager for API keys
- Audit Logs: All operations logged
- Kill Switch: Environment variable
AI_ENABLED=false - EU Region: All resources in
us-central1(configurable to EU regions)
Implementation
Shared Library: AI Client Abstraction
File: lib/ai_client.py
"""
AI Client abstraction for OpenAI and Vertex AI providers.
"""
import os
import time
from abc import ABC, abstractmethod
from typing import Dict, List, Optional, Tuple
from enum import Enum
try:
from google.cloud import aiplatform
from vertexai.preview.generative_models import GenerativeModel
except ImportError:
aiplatform = None
GenerativeModel = None
class AIProvider(str, Enum):
"""Supported AI providers."""
OPENAI = "openai"
VERTEX = "vertex"
class AIClient(ABC):
"""Abstract base class for AI clients."""
@abstractmethod
def generate(
self,
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
temperature: float = 0.7,
) -> Tuple[str, Dict[str, int]]:
"""
Generate a response from the AI model.
Returns:
Tuple of (response_text, token_usage_dict)
token_usage_dict contains: tokens_in, tokens_out
"""
pass
class VertexAIClient(AIClient):
"""Google Vertex AI client."""
def __init__(
self,
project_id: Optional[str] = None,
location: str = "us-central1",
model: str = "gemini-pro",
):
if GenerativeModel is None:
raise ImportError(
"vertexai package not installed. Install with: pip install google-cloud-aiplatform"
)
self.project_id = project_id or os.getenv("GCP_PROJECT_ID")
if not self.project_id:
raise ValueError("GCP_PROJECT_ID not provided")
self.location = location
self.model_name = model
aiplatform.init(project=self.project_id, location=self.location)
self.model = GenerativeModel(model)
def generate(
self,
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
temperature: float = 0.7,
) -> Tuple[str, Dict[str, int]]:
"""Generate response using Vertex AI."""
full_prompt = prompt
if system_prompt:
full_prompt = f"{system_prompt}\n\n{prompt}"
response = self.model.generate_content(
full_prompt,
generation_config={
"max_output_tokens": max_tokens,
"temperature": temperature,
},
)
content = response.text
token_usage = {
"tokens_in": len(full_prompt.split()) * 1.3, # Rough estimate
"tokens_out": len(content.split()) * 1.3, # Rough estimate
}
return content, token_usage
def get_ai_client(
provider: Optional[str] = None,
**kwargs
) -> AIClient:
"""
Factory function to get the appropriate AI client.
Args:
provider: "openai" or "vertex" (defaults to AI_PROVIDER env var)
**kwargs: Additional arguments passed to the client constructor
Returns:
AIClient instance
"""
provider = provider or os.getenv("AI_PROVIDER", AIProvider.VERTEX.value)
if provider == AIProvider.OPENAI.value:
return OpenAIClient(**kwargs)
elif provider == AIProvider.VERTEX.value:
return VertexAIClient(**kwargs)
else:
raise ValueError(f"Unknown AI provider: {provider}")
Kill Switch Implementation
File: lib/kill_switch.py
"""
Kill switch logic for disabling AI and falling back to deterministic outputs.
"""
import os
from typing import Dict, Any, Callable, Optional
def is_ai_enabled() -> bool:
"""Check if AI is enabled via environment variable."""
return os.getenv("AI_ENABLED", "true").lower() == "true"
def get_fallback_response(copilot_type: str) -> Dict[str, Any]:
"""
Get deterministic fallback response when AI is disabled.
Args:
copilot_type: "code", "reading", or "meeting"
Returns:
Dictionary with fallback response structure
"""
fallbacks = {
"code": {
"test_suggestions": [],
"refactor_hints": [],
"message": "AI is disabled. Please enable AI_ENABLED=true to get suggestions.",
},
"reading": {
"digest": [],
"follow_up_prompts": [],
"message": "AI is disabled. Please enable AI_ENABLED=true to get digest.",
},
"meeting": {
"action_items": [],
"message": "AI is disabled. Please enable AI_ENABLED=true to get action items.",
},
}
return fallbacks.get(copilot_type, {"message": "AI is disabled"})
def with_kill_switch(
ai_function: Callable,
copilot_type: str,
*args,
**kwargs
) -> Dict[str, Any]:
"""
Execute AI function with kill switch fallback.
Args:
ai_function: Function to call if AI is enabled
copilot_type: Type of copilot for fallback response
*args, **kwargs: Arguments to pass to ai_function
Returns:
Result from ai_function or fallback response
"""
if not is_ai_enabled():
return {
"result": get_fallback_response(copilot_type),
"ai_enabled": False,
"outcome": "fallback",
}
try:
result = ai_function(*args, **kwargs)
return {
"result": result,
"ai_enabled": True,
"outcome": "success",
}
except Exception as e:
return {
"result": get_fallback_response(copilot_type),
"ai_enabled": True,
"outcome": "error",
"error": str(e),
}
Code Copilot Service
File: copilots/code_copilot/main.py
"""
Code Copilot FastAPI service.
"""
import os
import sys
from typing import Optional
from fastapi import FastAPI, HTTPException, UploadFile, File, Form
from fastapi.responses import JSONResponse
from pydantic import BaseModel
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '../../'))
from lib.kill_switch import is_ai_enabled, with_kill_switch, get_fallback_response
from lib.bigquery_client import BigQueryClient
from copilots.code_copilot.copilot import CodeCopilot
app = FastAPI(title="Code Copilot", version="1.0.0")
copilot = CodeCopilot()
bq_client = BigQueryClient()
class CodeRequest(BaseModel):
"""Request model for code analysis."""
code: str
workflow: Optional[str] = None
corrections_needed: Optional[int] = None
class SuggestResponse(BaseModel):
"""Response model for suggestions."""
result: dict
latency_ms: Optional[int]
tokens_in: Optional[int]
tokens_out: Optional[int]
ai_enabled: bool
outcome: str
event_id: Optional[str] = None
@app.get("/health")
async def health():
"""Health check endpoint."""
return {"status": "healthy", "ai_enabled": is_ai_enabled()}
@app.post("/suggest", response_model=SuggestResponse)
async def suggest(
code: Optional[str] = Form(None),
file: Optional[UploadFile] = File(None),
workflow: Optional[str] = Form(None),
corrections_needed: Optional[int] = Form(None),
):
"""
Get code analysis suggestions.
Accepts either:
- code: Direct code text
- file: Uploaded code file
"""
# Get code content
code_content = code
if file:
code_content = await file.read()
code_content = code_content.decode('utf-8')
if not code_content:
raise HTTPException(status_code=400, detail="Either 'code' or 'file' must be provided")
input_bytes = len(code_content.encode('utf-8'))
def analyze():
return copilot.analyze_code(code_content)
response = with_kill_switch(analyze, "code")
telemetry = response["result"].get("telemetry", {})
latency_ms = telemetry.get("latency_ms")
tokens_in = telemetry.get("tokens_in", 0)
tokens_out = telemetry.get("tokens_out", 0)
cost_eur = None
if tokens_in and tokens_out:
cost_eur = (tokens_in / 1000 * 0.0005 + tokens_out / 1000 * 0.0005)
event_id = None
try:
event_id = bq_client.log_event(
copilot="code",
workflow=workflow,
freshness_tier="seconds",
input_bytes=input_bytes,
output_bytes=len(str(response["result"]).encode('utf-8')),
tokens_in=tokens_in,
tokens_out=tokens_out,
latency_ms=latency_ms,
ai_enabled=response["ai_enabled"],
corrections_needed=corrections_needed,
outcome=response["outcome"],
cost_eur=cost_eur,
)
except Exception as e:
print(f"Failed to log to BigQuery: {e}")
return SuggestResponse(
result=response["result"],
latency_ms=latency_ms,
tokens_in=tokens_in,
tokens_out=tokens_out,
ai_enabled=response["ai_enabled"],
outcome=response["outcome"],
event_id=event_id,
)
if __name__ == "__main__":
import uvicorn
port = int(os.getenv("PORT", 8080))
uvicorn.run(app, host="0.0.0.0", port=port)
File: copilots/code_copilot/copilot.py
"""
Code Copilot - AI-powered code analysis and suggestions.
"""
import sys
import os
from typing import Dict, List, Any
parent_dir = os.path.join(os.path.dirname(__file__), '../../')
sys.path.insert(0, parent_dir)
from lib.ai_client import get_ai_client
from lib.telemetry import Telemetry
class CodeCopilot:
"""Code Copilot for test suggestions and refactor hints."""
def __init__(self):
self.ai_client = get_ai_client()
self.system_prompt = """You are a code analysis assistant. Analyze code and provide:
1. Test case suggestions (unit tests, edge cases)
2. Refactoring hints (code quality, performance, maintainability)
Be concise and actionable. Format output as JSON with keys: test_suggestions (list) and refactor_hints (list)."""
def analyze_code(self, code: str) -> Dict[str, Any]:
"""
Analyze code and provide suggestions.
Args:
code: Source code to analyze
Returns:
Dictionary with test_suggestions and refactor_hints
"""
code_block = f"```python\n{code}\n```"
prompt = f"""Analyze the following code and provide test suggestions and refactoring hints:
{my_code_block}
Provide your analysis in JSON format with:
- test_suggestions: array of test case descriptions
- refactor_hints: array of refactoring suggestions"""
telemetry = Telemetry()
with telemetry.track():
response, token_usage = self.ai_client.generate(
prompt=prompt,
system_prompt=self.system_prompt,
max_tokens=2000,
temperature=0.7,
)
telemetry.set_tokens(token_usage["tokens_in"], token_usage["tokens_out"])
try:
import json
if "```json" in response:
json_start = response.find("```json") + 7
json_end = response.find("```", json_start)
response = response[json_start:json_end].strip()
elif "```" in response:
json_start = response.find("```") + 3
json_end = response.find("```", json_start)
response = response[json_start:json_end].strip()
result = json.loads(response)
except (json.JSONDecodeError, ValueError):
result = {
"test_suggestions": [response],
"refactor_hints": [],
}
return {
"test_suggestions": result.get("test_suggestions", []),
"refactor_hints": result.get("refactor_hints", []),
"telemetry": telemetry.to_dict(),
}
BigQuery Client
File: lib/bigquery_client.py
"""
BigQuery client for logging events and metrics.
"""
import os
import uuid
from datetime import datetime
from typing import Optional
try:
from google.cloud import bigquery
from google.cloud.exceptions import NotFound
except ImportError:
bigquery = None
NotFound = None
class BigQueryClient:
"""Client for logging events to BigQuery."""
def __init__(self, project_id: Optional[str] = None, dataset_id: str = "copilot_poc"):
if bigquery is None:
raise ImportError("google-cloud-bigquery not installed")
self.project_id = project_id or os.getenv("GCP_PROJECT_ID")
if not self.project_id:
raise ValueError("GCP_PROJECT_ID not provided")
self.dataset_id = dataset_id
self.client = bigquery.Client(project=self.project_id)
self._ensure_dataset_and_table()
def _ensure_dataset_and_table(self):
"""Ensure dataset and table exist."""
dataset_ref = self.client.dataset(self.dataset_id)
try:
self.client.get_dataset(dataset_ref)
except NotFound:
dataset = bigquery.Dataset(dataset_ref)
dataset.location = "US"
dataset.description = "Dataset for storing copilot events and metrics"
self.client.create_dataset(dataset)
table_ref = dataset_ref.table("events")
try:
self.client.get_table(table_ref)
except NotFound:
schema = [
bigquery.SchemaField("event_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("ts", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("copilot", "STRING", mode="REQUIRED"),
bigquery.SchemaField("workflow", "STRING"),
bigquery.SchemaField("freshness_tier", "STRING"),
bigquery.SchemaField("input_bytes", "INT64"),
bigquery.SchemaField("output_bytes", "INT64"),
bigquery.SchemaField("tokens_in", "INT64"),
bigquery.SchemaField("tokens_out", "INT64"),
bigquery.SchemaField("latency_ms", "INT64"),
bigquery.SchemaField("ai_enabled", "BOOL"),
bigquery.SchemaField("corrections_needed", "INT64"),
bigquery.SchemaField("outcome", "STRING"),
bigquery.SchemaField("cost_eur", "NUMERIC"),
bigquery.SchemaField("notes", "STRING"),
]
table = bigquery.Table(table_ref, schema=schema)
table.time_partitioning = bigquery.TimePartitioning(field="ts")
table.clustering_fields = ["copilot", "outcome"]
self.client.create_table(table)
def log_event(
self,
copilot: str,
workflow: Optional[str] = None,
freshness_tier: str = "seconds",
input_bytes: Optional[int] = None,
output_bytes: Optional[int] = None,
tokens_in: Optional[int] = None,
tokens_out: Optional[int] = None,
latency_ms: Optional[int] = None,
ai_enabled: bool = True,
corrections_needed: Optional[int] = None,
outcome: str = "success",
cost_eur: Optional[float] = None,
notes: Optional[str] = None,
) -> str:
"""
Log an event to BigQuery.
Returns:
event_id: Unique identifier for the logged event
"""
event_id = str(uuid.uuid4())
row = {
"event_id": event_id,
"ts": datetime.utcnow().isoformat(),
"copilot": copilot,
"workflow": workflow,
"freshness_tier": freshness_tier,
"input_bytes": input_bytes,
"output_bytes": output_bytes,
"tokens_in": tokens_in,
"tokens_out": tokens_out,
"latency_ms": latency_ms,
"ai_enabled": ai_enabled,
"corrections_needed": corrections_needed,
"outcome": outcome,
"cost_eur": cost_eur,
"notes": notes,
}
table_ref = self.client.dataset(self.dataset_id).table("events")
errors = self.client.insert_rows_json(table_ref, [row])
if errors:
raise Exception(f"Failed to insert row: {errors}")
return event_id
Telemetry Library
File: lib/telemetry.py
"""
Telemetry tracking for latency and token usage.
"""
import time
from typing import Dict, Optional
class Telemetry:
"""Track latency and token usage for AI operations."""
def __init__(self):
self.start_time: Optional[float] = None
self.end_time: Optional[float] = None
self.tokens_in: int = 0
self.tokens_out: int = 0
def __enter__(self):
self.start_time = time.time()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.end_time = time.time()
def track(self):
"""Context manager for tracking latency."""
return self
def set_tokens(self, tokens_in: int, tokens_out: int):
"""Set token usage."""
self.tokens_in = tokens_in
self.tokens_out = tokens_out
@property
def latency_ms(self) -> Optional[int]:
"""Get latency in milliseconds."""
if self.start_time and self.end_time:
return int((self.end_time - self.start_time) * 1000)
return None
def to_dict(self) -> Dict[str, any]:
"""Convert to dictionary."""
return {
"latency_ms": self.latency_ms,
"tokens_in": self.tokens_in,
"tokens_out": self.tokens_out,
}
Terraform Infrastructure
File: infrastructure/modules/cloud_run/main.tf
variable "project_id" {
description = "GCP Project ID"
type = string
}
variable "region" {
description = "GCP Region"
type = string
default = "eu-west4"
}
variable "service_name" {
description = "Cloud Run service name"
type = string
}
variable "image" {
description = "Container image URL"
type = string
}
variable "service_account_email" {
description = "Service account email"
type = string
}
variable "environment_variables" {
description = "Environment variables"
type = map(string)
default = {}
}
variable "min_instances" {
description = "Minimum number of instances"
type = number
default = 0 # Scale to zero for cost optimization
}
variable "max_instances" {
description = "Maximum number of instances"
type = number
default = 3 # Limit max instances for cost control
}
resource "google_cloud_run_service" "service" {
name = var.service_name
location = var.region
project = var.project_id
template {
spec {
service_account_name = var.service_account_email
containers {
image = var.image
resources {
limits = {
cpu = "1"
memory = "512Mi"
}
}
dynamic "env" {
for_each = var.environment_variables
content {
name = env.key
value = env.value
}
}
}
container_concurrency = 80
timeout_seconds = 300
}
metadata {
annotations = {
"autoscaling.knative.dev/minScale" = tostring(var.min_instances)
"autoscaling.knative.dev/maxScale" = tostring(var.max_instances)
}
labels = {
environment = "dev"
service = var.service_name
}
}
}
traffic {
percent = 100
latest_revision = true
}
}
# Private access only (bearer token authentication)
resource "google_cloud_run_service_iam_member" "authenticated_access" {
service = google_cloud_run_service.service.name
location = google_cloud_run_service.service.location
role = "roles/run.invoker"
member = "serviceAccount:${var.service_account_email}"
}
output "service_url" {
description = "Cloud Run service URL"
value = google_cloud_run_service.service.status[0].url
}
BigQuery Schema
File: scripts/setup_bigquery.sql
-- BigQuery Setup Script for Copilot PoC
-- Dataset: copilot_poc
-- Create dataset
CREATE SCHEMA IF NOT EXISTS `copilot_poc`
OPTIONS(
description="Dataset for storing copilot events and metrics",
location="US"
);
-- Events table
CREATE TABLE IF NOT EXISTS `copilot_poc.events` (
event_id STRING NOT NULL,
ts TIMESTAMP NOT NULL,
copilot STRING NOT NULL,
workflow STRING,
freshness_tier STRING,
input_bytes INT64,
output_bytes INT64,
tokens_in INT64,
tokens_out INT64,
latency_ms INT64,
ai_enabled BOOL,
corrections_needed INT64,
outcome STRING,
cost_eur NUMERIC,
notes STRING
)
PARTITION BY DATE(ts)
CLUSTER BY copilot, outcome
OPTIONS(
description="One row per copilot invocation with full telemetry"
);
-- Catalog table
CREATE TABLE IF NOT EXISTS `copilot_poc.catalog` (
workflow STRING NOT NULL,
copilot STRING NOT NULL,
owner STRING,
freshness_tier STRING,
sla_ms INT64
)
OPTIONS(
description="Workflow registry with freshness tiers and SLAs"
);
-- Insert catalog entries
INSERT INTO `copilot_poc.catalog` (workflow, copilot, owner, freshness_tier, sla_ms)
VALUES
('code-copilot-workflow', 'code', 'dev-team', 'seconds', 2000),
('reading-copilot-nightly', 'reading', 'dev-team', 'daily', 300000),
('meeting-copilot-workflow', 'meeting', 'dev-team', 'minutes', 60000)
ON DUPLICATE KEY UPDATE
copilot = EXCLUDED.copilot,
owner = EXCLUDED.owner,
freshness_tier = EXCLUDED.freshness_tier,
sla_ms = EXCLUDED.sla_ms;
-- Metrics view (daily aggregates)
CREATE OR REPLACE VIEW `copilot_poc.metrics` AS
SELECT
DATE(ts) as date,
copilot,
COUNT(*) as total_events,
AVG(latency_ms) as avg_latency_ms,
APPROX_QUANTILES(latency_ms, 100)[OFFSET(95)] as p95_latency_ms,
SUM(tokens_in) as total_tokens_in,
SUM(tokens_out) as total_tokens_out,
SUM(cost_eur) as total_cost_eur,
AVG(corrections_needed) as avg_corrections,
COUNTIF(outcome = 'success') as success_count,
COUNTIF(outcome = 'fallback') as fallback_count,
COUNTIF(outcome = 'error') as error_count,
COUNTIF(outcome = 'success') / COUNT(*) as success_rate
FROM
`copilot_poc.events`
GROUP BY
date, copilot
ORDER BY
date DESC, copilot;
Testing Strategy
Unit Tests
File: tests/test_kill_switch.py
"""
Unit tests for kill switch functionality.
"""
import os
import pytest
from unittest.mock import patch, MagicMock
from lib.kill_switch import is_ai_enabled, get_fallback_response, with_kill_switch
def test_is_ai_enabled_true():
"""Test AI enabled when environment variable is true."""
with patch.dict(os.environ, {"AI_ENABLED": "true"}):
assert is_ai_enabled() is True
def test_is_ai_enabled_false():
"""Test AI disabled when environment variable is false."""
with patch.dict(os.environ, {"AI_ENABLED": "false"}):
assert is_ai_enabled() is False
def test_is_ai_enabled_default():
"""Test AI enabled by default when environment variable is not set."""
with patch.dict(os.environ, {}, clear=True):
assert is_ai_enabled() is True
def test_get_fallback_response_code():
"""Test fallback response for code copilot."""
response = get_fallback_response("code")
assert "test_suggestions" in response
assert "refactor_hints" in response
assert "message" in response
assert response["test_suggestions"] == []
assert response["refactor_hints"] == []
def test_get_fallback_response_reading():
"""Test fallback response for reading copilot."""
response = get_fallback_response("reading")
assert "digest" in response
assert "follow_up_prompts" in response
assert "message" in response
def test_with_kill_switch_disabled():
"""Test kill switch when AI is disabled."""
with patch.dict(os.environ, {"AI_ENABLED": "false"}):
mock_function = MagicMock()
result = with_kill_switch(mock_function, "code")
assert result["ai_enabled"] is False
assert result["outcome"] == "fallback"
assert "result" in result
mock_function.assert_not_called()
def test_with_kill_switch_enabled_success():
"""Test kill switch when AI is enabled and succeeds."""
with patch.dict(os.environ, {"AI_ENABLED": "true"}):
mock_function = MagicMock(return_value={"test": "result"})
result = with_kill_switch(mock_function, "code")
assert result["ai_enabled"] is True
assert result["outcome"] == "success"
assert result["result"] == {"test": "result"}
mock_function.assert_called_once()
def test_with_kill_switch_enabled_error():
"""Test kill switch when AI is enabled but fails."""
with patch.dict(os.environ, {"AI_ENABLED": "true"}):
mock_function = MagicMock(side_effect=Exception("AI error"))
result = with_kill_switch(mock_function, "code")
assert result["ai_enabled"] is True
assert result["outcome"] == "error"
assert "error" in result
assert result["error"] == "AI error"
File: tests/test_ai_client.py
"""
Unit tests for AI client abstraction.
"""
import pytest
from unittest.mock import patch, MagicMock
from lib.ai_client import get_ai_client, VertexAIClient, AIProvider
@patch('lib.ai_client.aiplatform')
@patch('lib.ai_client.GenerativeModel')
def test_vertex_ai_client_init(mock_model_class, mock_aiplatform):
"""Test Vertex AI client initialization."""
mock_model = MagicMock()
mock_model_class.return_value = mock_model
with patch.dict(os.environ, {"GCP_PROJECT_ID": "test-project"}):
client = VertexAIClient(
project_id="test-project",
location="us-central1",
model="gemini-pro"
)
assert client.project_id == "test-project"
assert client.location == "us-central1"
assert client.model_name == "gemini-pro"
mock_aiplatform.init.assert_called_once()
mock_model_class.assert_called_once_with("gemini-pro")
@patch('lib.ai_client.aiplatform')
@patch('lib.ai_client.GenerativeModel')
def test_vertex_ai_client_generate(mock_model_class, mock_aiplatform):
"""Test Vertex AI client generate method."""
mock_model = MagicMock()
mock_response = MagicMock()
mock_response.text = "Test response"
mock_model.generate_content.return_value = mock_response
mock_model_class.return_value = mock_model
with patch.dict(os.environ, {"GCP_PROJECT_ID": "test-project"}):
client = VertexAIClient()
response, token_usage = client.generate(
prompt="Test prompt",
system_prompt="System prompt",
max_tokens=1000,
temperature=0.7
)
assert response == "Test response"
assert "tokens_in" in token_usage
assert "tokens_out" in token_usage
mock_model.generate_content.assert_called_once()
File: tests/test_code_copilot.py
"""
Unit tests for code copilot.
"""
import pytest
from unittest.mock import patch, MagicMock
from copilots.code_copilot.copilot import CodeCopilot
@patch('copilots.code_copilot.copilot.get_ai_client')
def test_code_copilot_analyze_code(mock_get_client):
"""Test code copilot analyze_code method."""
mock_client = MagicMock()
mock_client.generate.return_value = (
'{"test_suggestions": ["Test 1", "Test 2"], "refactor_hints": ["Hint 1"]}',
{"tokens_in": 100, "tokens_out": 50}
)
mock_get_client.return_value = mock_client
copilot = CodeCopilot()
result = copilot.analyze_code("def test(): pass")
assert "test_suggestions" in result
assert "refactor_hints" in result
assert "telemetry" in result
assert len(result["test_suggestions"]) == 2
assert len(result["refactor_hints"]) == 1
assert result["telemetry"]["tokens_in"] == 100
assert result["telemetry"]["tokens_out"] == 50
Integration Tests
File: tests/integration/test_copilot_integration.py
"""
Integration tests for copilot services.
"""
import pytest
import os
from fastapi.testclient import TestClient
from copilots.code_copilot.main import app
@pytest.fixture
def client():
"""Create test client."""
return TestClient(app)
def test_health_endpoint(client):
"""Test health endpoint."""
response = client.get("/health")
assert response.status_code == 200
data = response.json()
assert "status" in data
assert "ai_enabled" in data
@patch.dict(os.environ, {"AI_ENABLED": "false"})
def test_suggest_endpoint_kill_switch(client):
"""Test suggest endpoint with kill switch disabled."""
response = client.post(
"/suggest",
data={"code": "def test(): pass"}
)
assert response.status_code == 200
data = response.json()
assert data["ai_enabled"] is False
assert data["outcome"] == "fallback"
Performance Tests
File: tests/performance/test_latency.py
"""
Performance tests for latency requirements.
"""
import pytest
import time
from copilots.code_copilot.copilot import CodeCopilot
def test_code_copilot_latency_seconds_tier():
"""Test code copilot meets seconds-tier latency requirement."""
copilot = CodeCopilot()
start_time = time.time()
result = copilot.analyze_code("def test(): pass")
elapsed_ms = (time.time() - start_time) * 1000
# Seconds tier: p95 < 2000ms
assert elapsed_ms < 2000, f"Latency {elapsed_ms}ms exceeds 2000ms SLA"
assert "telemetry" in result
assert result["telemetry"]["latency_ms"] < 2000
End-to-End Tests
File: tests/e2e/test_full_workflow.py
"""
End-to-end tests for full copilot workflow.
"""
import pytest
import requests
import os
@pytest.mark.e2e
def test_code_copilot_e2e():
"""Test full code copilot workflow end-to-end."""
service_url = os.getenv("CODE_COPILOT_URL", "http://localhost:8080")
# Test health check
health_response = requests.get(f"{service_url}/health")
assert health_response.status_code == 200
# Test code analysis
code = """
def calculate_total(items):
total = 0
for item in items:
total += item.price
return total
"""
suggest_response = requests.post(
f"{service_url}/suggest",
data={"code": code}
)
assert suggest_response.status_code == 200
data = suggest_response.json()
assert "result" in data
assert "event_id" in data
Measurement & Metrics
BigQuery Queries
Daily Metrics:
SELECT * FROM `copilot_poc.metrics`
WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
ORDER BY date DESC, copilot;
Time Saved Calculation:
SELECT
copilot,
AVG(latency_ms) as avg_copilot_time_ms,
CASE
WHEN copilot = 'code' THEN 10000
WHEN copilot = 'reading' THEN 300000
WHEN copilot = 'meeting' THEN 720000
ELSE 0
END as baseline_time_ms,
CASE
WHEN copilot = 'code' THEN (10000 - AVG(latency_ms)) / 10000.0 * 100
WHEN copilot = 'reading' THEN (300000 - AVG(latency_ms)) / 300000.0 * 100
WHEN copilot = 'meeting' THEN (720000 - AVG(latency_ms)) / 720000.0 * 100
ELSE 0
END as time_saved_percent
FROM
`copilot_poc.events`
WHERE
outcome = 'success'
AND DATE(ts) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
GROUP BY
copilot;
Cost per 1K Predictions:
SELECT
copilot,
COUNT(*) as total_predictions,
SUM(cost_eur) as total_cost_eur,
SUM(cost_eur) / COUNT(*) * 1000 as cost_per_1k_predictions_eur
FROM
`copilot_poc.events`
WHERE
outcome = 'success'
AND cost_eur IS NOT NULL
AND DATE(ts) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
GROUP BY
copilot;
Kill Switch Effectiveness:
SELECT
DATE(ts) as date,
copilot,
COUNTIF(outcome = 'fallback') as fallback_count,
COUNTIF(outcome = 'success') as success_count,
COUNTIF(outcome = 'fallback') / COUNT(*) * 100 as fallback_rate
FROM
`copilot_poc.events`
WHERE
DATE(ts) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
GROUP BY
date, copilot
ORDER BY
date DESC, copilot;
Quality Metrics (Edits Reduced):
SELECT
copilot,
AVG(corrections_needed) as avg_corrections_with_copilot,
CASE
WHEN copilot = 'code' THEN 5.0
WHEN copilot = 'reading' THEN 8.0
WHEN copilot = 'meeting' THEN 6.0
ELSE 0
END as baseline_corrections,
CASE
WHEN copilot = 'code' THEN (5.0 - AVG(corrections_needed)) / 5.0 * 100
WHEN copilot = 'reading' THEN (8.0 - AVG(corrections_needed)) / 8.0 * 100
WHEN copilot = 'meeting' THEN (6.0 - AVG(corrections_needed)) / 6.0 * 100
ELSE 0
END as edits_reduced_percent
FROM
`copilot_poc.events`
WHERE
outcome = 'success'
AND corrections_needed IS NOT NULL
AND DATE(ts) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
GROUP BY
copilot;
Results
Reading Copilot
Hypothesis: H1 (time saved), H2 (edits reduced), H3 (cost)
Results:
- Time saved: 17% (median over 5 runs)
- Edits reduced: 21% vs. baseline
- Cost: €0.01/task (daily batch)
- p95 latency: 45 seconds (within daily tier SLA)
- Status: PASSED - Kept
Analysis:
Daily batch processing eliminated real-time costs while meeting the “fresh enough” requirement. The 10-bullet digest format reduced cognitive load and editing time.
Meeting Copilot
Hypothesis: H1 (time saved), H2 (edits reduced), H4 (latency)
Results:
- Time saved: 20% (median over 5 runs)
- Edits reduced: 22% vs. baseline
- p95 latency: 2.5 minutes (within minutes tier SLA)
- Cost: €0.02/task
- Status: PASSED - Kept
Analysis:
Structured action items with owners and deadlines reduced follow-up time. The minutes-tier freshness met the use case without requiring real-time processing.
Code Copilot
Hypothesis: H1 (time saved), H2 (edits reduced), H4 (latency)
Results:
- Time saved: 8% (median over 5 runs) - Below 15% threshold
- Edits reduced: 12% vs. baseline - Below 20% threshold
- p95 latency: 1.8 seconds (within seconds tier SLA)
- Cost: €0.005/task
- Status: FAILED - Retired
Analysis:
While latency was acceptable, the time saved and edit reduction didn’t meet the success gates. The copilot was helpful but not transformative enough to justify keeping. Future experiments with on-device models or better prompts may improve results.
Kill Switch
Hypothesis: H5 (reversibility)
Results:
- Fallback success rate: 100% (10/10 tests)
- Response time: <50ms (deterministic fallback)
- Logging: All fallback events logged to BigQuery
- Status: PASSED
Analysis:
The kill switch provided clean reversibility with zero AI API calls when disabled. All fallback events were logged, enabling audit trails.
Governance & Trust
Model Card: AI Copilots PoC
Model Details
- Provider: Google Vertex AI (Gemini-Pro)
- Region: eu-west4
- Use Case: Personal workflow assistance (reading, meetings, code)
Intended Use
- Reading Copilot: Generate 10-bullet digests from documents
- Meeting Copilot: Extract action items with owners and deadlines
- Code Copilot: Suggest test cases and refactoring hints
Limitations
- No business data or PII processing
- Personal use only
- Outputs require human review
- No guarantees on accuracy or completeness
Failure Modes
- API outages -> Kill switch activates
- Cost spikes -> Kill switch activates
- Quality regression -> Manual review and kill switch if needed
Bias & Safety
- Prompts designed to avoid absolute claims
- Citations encouraged when possible
- Human-in-the-loop for all outputs
Bias Checklist
Pre-Deployment
- Prompts reviewed for bias
- Output formats structured to reduce interpretation errors
- Kill switch tested and documented
- Audit logs enabled
During Operation
- Monitor for quality regression
- Track corrections_needed metric
- Review fallback events
- Cost monitoring alerts
Post-Deployment
- Review outcomes weekly
- Compare against baseline metrics
- Document failures and learnings
What Failed & Why
Code Copilot Retirement
Why it failed:
- Time saved (8%) below 15% threshold
- Edits reduced (12%) below 20% threshold
- Helpful but not transformative
Lessons:
- Not all tasks need generative AI
- Right-time beats real-time (reading copilot succeeded with daily batch)
- Small scope wins (easier to measure and decide)
Next steps:
- Experiment with on-device models for lower latency/privacy
- Try different prompts or fine-tuning
- Consider rule-based alternatives for code analysis
Reproducible Pattern
One-Page Playbook
1. Start Tiny
- One copilot, one endpoint, one metric table
- Measure baseline honestly (5+ runs)
2. Map Freshness to Decisions
- Seconds: User waiting (interactive)
- Minutes: Acceptable delay (post-processing)
- Daily: No user waiting (batch)
3. Add Kill Switch
- Environment variable:
AI_ENABLED=false - Deterministic fallback responses
- Log all fallback events
4. Measure Strictly
- Time saved (median over 5+ runs)
- Edits reduced vs. baseline
- Cost per task
- p95 latency within SLA
5. Keep Only What Beats Control
- ≥15% time saved
- ≥20% fewer edits
- Stable cost
- Stop the rest
Conclusion
This PoC proved that small, measurable AI helpers can deliver real value when:
- Freshness is mapped to decisions (right-time, not real-time)
- Success gates are strict (≥15% time saved, ≥20% fewer edits)
- A kill switch provides reversibility
- Cost is predictable and monitored
Two copilots passed, one failed and was retired. The pattern is portable, governed, and repeatable - ready to template for other workflows.
Author: Dr. Atabak Kheirkhah
Date: November 17, 2025
Contact: atabakkheirkhah@gmail.com
This is a personal blog. The views, thoughts, and opinions expressed here are my own and do not represent, reflect, or constitute the views, policies, or positions of any employer, university, client, or organization I am associated with or have been associated with.