DR. ATABAK KH
Cloud Platform Modernization Architect specializing in transforming legacy systems into reliable, observable, and cost-efficient Cloud platforms.
Certified: Google Professional Cloud Architect, AWS Solutions Architect, MapR Cluster Administrator
Human Risk, Fast AI, Slow Thinking: Innovation, Greed, and the Quiet Risk to Our Data
Published on 30 November 2025.
Tags: human risk, ai-security, data-governance, enterprise-ai, privacy, responsible-ai, risk-management
When I was doing my PhD, I spent years building computational models for cancer detection. It sounded glamorous from the outside - algorithms, prediction, science. In reality it was a constant confrontation with risk and of course data as bigggg considration.
The data I worked with was deeply personal: gene expression profiles, clinical records, diagnostic outcomes. If my models were wrong, real people paid the price. A “good enough” model was not good enough. We had to think about:
- How the data was collected
- How it was stored and anonymised
- How predictions could be misinterpreted
- What could happen if something leaked
This mindset is exactly what I miss today when I look at how many companies are “doing AI”.
Right now, the narrative is simple and brutal:
Move fast, plug in AI everywhere, and worry about the details later.
From my perspective, that’s not innovation. That’s negligence dressed up as progress.
Table of Contents
- Background: The Data Leakage Crisis
- The Problem: Greedy AI Adoption
- How Data Really Leaks Through AI
- Methodology: A Risk-Based Framework
- Implementation: Five-Step Secure AI Architecture
- Technical Controls and Architecture
- Governance and Policy Framework
- Case Studies and Real-World Examples
- Conclusion: AI with Discipline
Background: The Data Leakage Crisis
The Everyday AI That Quietly Eats Your Data
Let’s be honest about what’s actually happening inside every companies.
Employees are under pressure to deliver more, faster. They discover a large language model that can summarise, generate, and debug in seconds ( and honestly not eveyone underestand right know what are you doing???? ). So they start doing what feels natural:
- Paste internal documents into chatbots to “summarise this for me”
- Paste source code and logs to “help me debug this”
- Paste HR policies, contracts, even customer data to “make this clearer”
Nobody is trying to be malicious. People are just trying to survive their workday.
The problem is simple:
The moment that data leaves your controlled environment and lands in a third-party AI tool, you’ve lost control.
You don’t really know:
- How long the data is stored
- How big the data would stored
- what data is going to be stored
- Who exactly can access it
- Whether it might be used for training
- How it might resurface in another context
- ….
In my PhD world, that level of uncertainty would have killed any project immediately. In today’s corporate world, it often doesn’t even stop a pilot.
The Scale of the Problem
Recent studies and incidents reveal the scope:
- 2023: Samsung engineers leaked proprietary code via ChatGPT
- 2024: Multiple healthcare organizations exposed patient data through AI tools
- Ongoing: Thousands of companies have no policy on AI data usage
The pattern is consistent: well-intentioned employees, no guardrails, predictable outcomes.
The Problem: Greedy AI Adoption vs. Responsible Use
We can talk about ethics and principles, but let’s be direct: a lot of AI adoption is driven by greed and fear.
The Drivers
- Greed for valuation - “We are now an AI company” is cheaper than actually fixing your product
- Greed for KPIs - More users, more engagement, lower cost per ticket
- Fear of missing out - “If we don’t do it, our competitors will”
In this context, “AI strategy” often means:
- Add AI to the landing page
- Integrate with the first big LLM API available
- Hope the security team signs off later
This might “work” short term, especially in startups desperate for growth. But structurally it creates a fragile system:
- No data classification
- No clear policy on PII
- No guardrails against employees leaking sensitive information
- No real incident response plan if something goes wrong
You end up with a strange paradox:
Companies shout about “AI transformation” while quietly gambling with the data that keeps them alive.
Human Safety and Company Safety Are Not Opposites
There’s a dangerous myth that human safety and business interests are in tension.
From what I’ve seen on both sides - research and industry - the opposite is true:
- If you misuse personal data, you lose customer trust
- If your AI behaves unpredictably in critical domains (health, finance, hiring), regulators and courts will eventually come
- If your internal knowledge, code, or strategy leaks through AI tools, your competitive advantage evaporates
Protecting people and protecting the company are the same problem with different time horizons.
In my PhD project, we could not hide behind “we are just experimenting”. We had to assume:
- Someone might act on these predictions.
- Someone might be harmed by them.
- Someone will ask us to defend our methods.
Companies deploying AI at scale should assume exactly the same.
How Data Really Leaks Through AI
Most leaks don’t look like a Hollywood hack. They look like normal work.
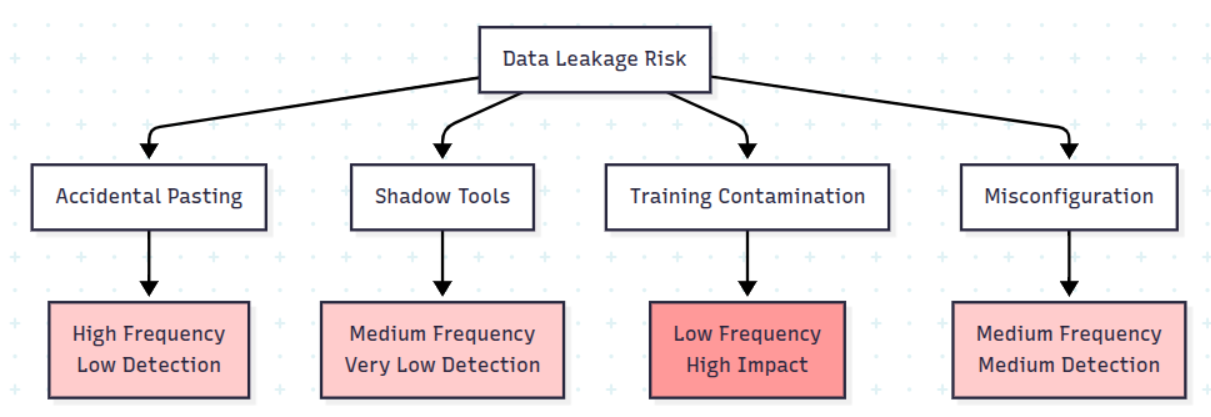
The Four Main Leakage Vectors
1. Accidental Pasting
Pattern:
- A developer pastes proprietary code into a chatbot
- A manager pastes an internal strategy deck for “summarisation”
- A recruiter pastes a list of candidates with full details to write “better outreach emails”
Why it happens:
- No clear policy on what’s allowed
- No technical controls preventing it
- Pressure to deliver quickly
2. Shadow Tools
Pattern:
- Browser extensions, plugins, or unofficial AI helpers that quietly send snippets of screen content to external services
- Personal accounts used for “quick help” on work documents
Why it happens:
- IT doesn’t control all tools employees use
- Personal devices and accounts blur boundaries
- No monitoring of data egress
3. Training Data Contamination
Pattern:
- Scraped datasets that include PII or confidential documents
- Models later regurgitate pieces of those documents when probed in specific ways
Why it happens:
- Training data sources not vetted
- No data minimization in model training
- Models retain more information than expected
4. Misconfiguration and Bugs
Pattern:
- Wrong access settings, test environments made public
- Shared logs that contain prompts and responses
- API keys exposed in code repositories
Why it happens:
- Rush to deploy
- No security review process
- Default settings are permissive
None of this is spectacular. It’s routine. That’s exactly why it’s so dangerous.
Data Leakage Risk Matrix
Methodology: A Risk-Based Framework
If a company genuinely wants to adopt AI without playing roulette with data and trust, it needs something more mature than “let’s try this API”.
Core Principles
- Data Classification First - Know what you have before you protect it
- Risk-Based Approach - Not all AI features are equal
- Defense in Depth - Technical controls + policy + training
- Measurable Outcomes - Track incidents, near misses, trust metrics
- Reversibility - Kill switches and fallback mechanisms
The Framework Structure

Implementation: Five-Step Secure AI Architecture
A minimal, workable approach can be broken into five steps.
Step 1: Classify Your Data First
Before touching AI, be explicit:
Data Classification Levels:
- Public - Can safely be sent anywhere (marketing copy, public documentation)
- Internal Non-Sensitive - Inconvenient if leaked, but survivable (internal process docs, non-confidential policies)
- Confidential - Source code, architecture, contracts, internal strategy
- PII / Highly Sensitive - Customer data, HR data, health data, financial records
Clear Rules:
- Public: OK with external AI tools
- Internal Non-Sensitive: Only with approved tools and vendors
- Confidential & PII: Never to public AI; only via controlled, private models with contracts and technical safeguards
If a company can’t answer “what data do we actually have and how sensitive is it?”, then it has no business deploying AI on top of it.
Step 2: Classify Your AI Use Cases by Risk
Not all AI features are equal. A marketing text generator and an AI system deciding who gets a loan do not belong in the same risk category.
Risk Assessment Matrix:
Define two dimensions:
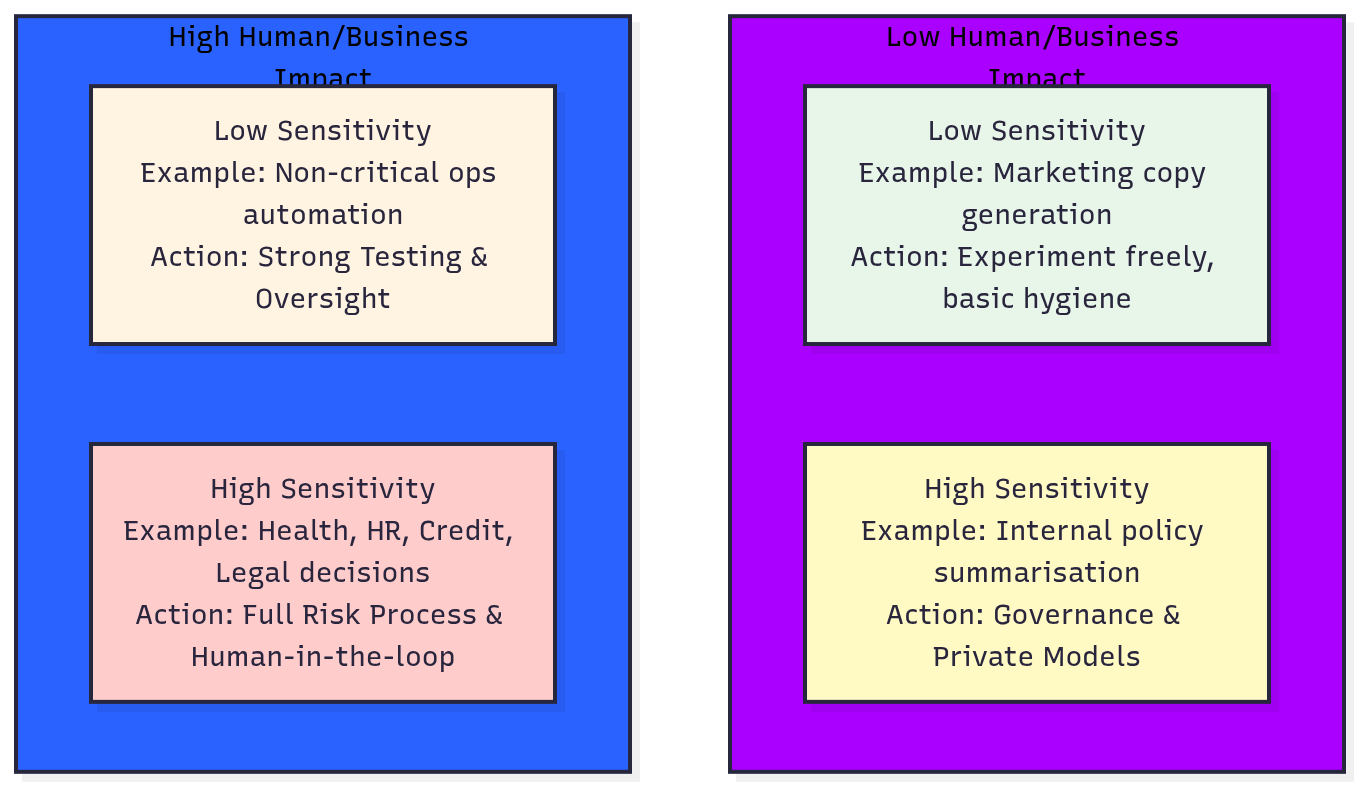
- Data Sensitivity (low / high)
- Human & Business Impact (low / high)
You then get four quadrants:
Decision Framework:
- Low sensitivity, low impact –> “Experiment freely, with basic hygiene”
- High sensitivity or high impact –> “Formal assessment, documented controls, human oversight, and very careful rollout”
Anything high-impact + high-sensitivity should be treated like a medical model: audited, tested, explainable, and reversible.
Step 3: Design AI Architecture With Controls, Not Just Features
A secure AI setup is more than “user –> LLM API”.
You need an internal layer that:
- Filters and redacts sensitive data where possible (data minimisation)
- Enforces policies (“no PII to external models”)
- Logs all requests and responses for audit and incident analysis
- Routes sensitive workloads to private / VPC-isolated models
Most companies go wrong by integrating AI at the edge (direct from browser to vendor). You want AI behind an internal gateway that you control.
Step 4: Set Policy, Ownership, and Training
People are not going to guess the right behaviour. You must be explicit.
Required Elements:
- A clear AI usage policy: what tools are allowed, forbidden, and under what constraints
- A clear owner (or committee) for AI risk and governance
- Regular training for employees: what is PII, what counts as confidential, concrete examples of “do” and “don’t”
If AI is “everyone’s job” but nobody is accountable, risk will accumulate silently until something breaks.
Step 5: Monitor, Learn, and Treat Incidents as Feedback
Assume mistakes. Then build for them.
Monitoring Requirements:
- Monitor AI usage and look for abnormal patterns
- Have a basic incident response plan: who is involved, what gets shut down, how you communicate
- After each incident or near miss, update policies and controls, not just the slide deck
Companies that pretend “nothing bad will happen” with AI are signalling that they have no realistic understanding of how technology fails in the real world.
Technical Controls and Architecture
Secure AI Data Flow Architecture
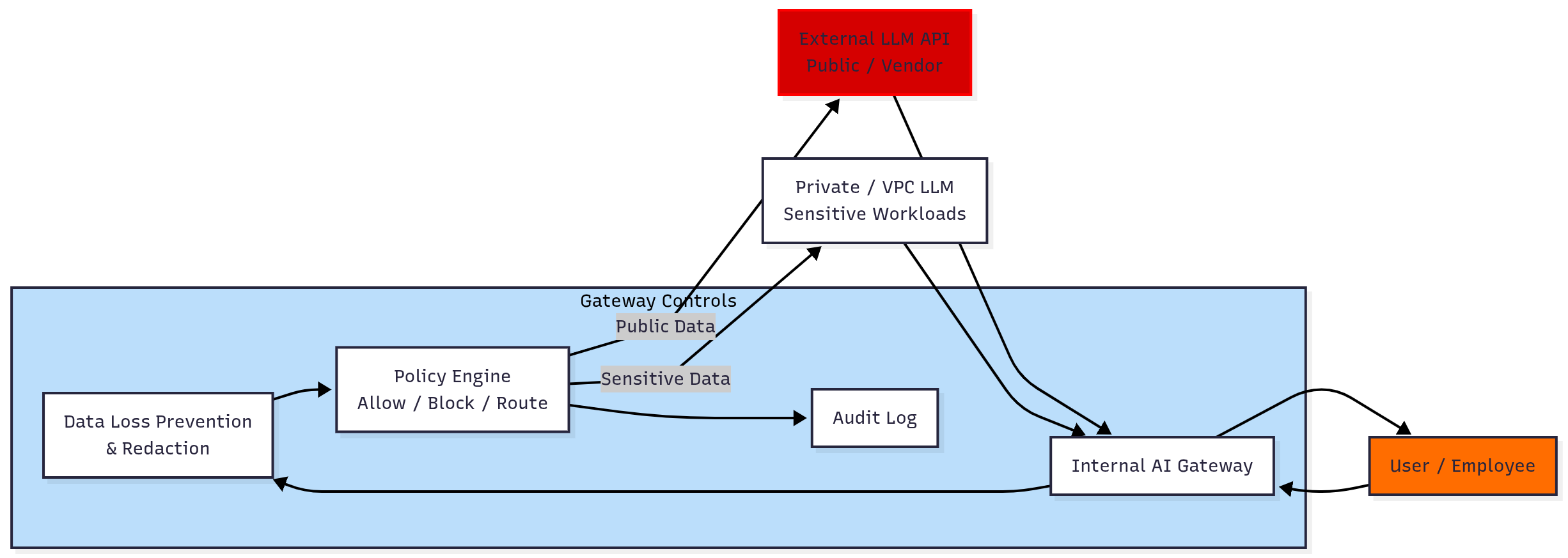
Implementation Example: AI Gateway Service
Architecture Components:
- API Gateway - Routes all AI requests
- Data Loss Prevention (DLP) - Scans and redacts sensitive data
- Policy Engine - Enforces data classification rules
- Audit Logger - Records all AI interactions
- Routing Layer - Directs requests to appropriate AI provider
Example Implementation (Python/FastAPI):
"""
AI Gateway Service - Secure routing and policy enforcement
"""
from fastapi import FastAPI, HTTPException, Request
from pydantic import BaseModel
from typing import Optional, Dict, Any
import logging
from datetime import datetime
# Data classification
class DataClassification:
PUBLIC = "public"
INTERNAL = "internal"
CONFIDENTIAL = "confidential"
PII = "pii"
# DLP Service
class DLPService:
"""Data Loss Prevention - detects and redacts sensitive data"""
def classify_data(self, content: str) -> str:
"""Classify data sensitivity level"""
# PII detection patterns
pii_patterns = [
r'\b\d{3}-\d{2}-\d{4}\b', # SSN
r'\b\d{16}\b', # Credit card
r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', # Email
]
import re
for pattern in pii_patterns:
if re.search(pattern, content):
return DataClassification.PII
# Confidential keywords
confidential_keywords = ['proprietary', 'confidential', 'internal strategy']
if any(keyword in content.lower() for keyword in confidential_keywords):
return DataClassification.CONFIDENTIAL
return DataClassification.PUBLIC
def redact_sensitive(self, content: str, classification: str) -> str:
"""Redact sensitive data based on classification"""
if classification == DataClassification.PII:
# Redact PII patterns
import re
content = re.sub(r'\b\d{3}-\d{2}-\d{4}\b', '[SSN-REDACTED]', content)
content = re.sub(r'\b\d{16}\b', '[CARD-REDACTED]', content)
content = re.sub(
r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
'[EMAIL-REDACTED]',
content
)
return content
# Policy Engine
class PolicyEngine:
"""Enforces AI usage policies based on data classification"""
def __init__(self):
self.rules = {
DataClassification.PUBLIC: {
"allowed_providers": ["openai", "anthropic", "google"],
"requires_approval": False,
},
DataClassification.INTERNAL: {
"allowed_providers": ["openai-enterprise", "anthropic-enterprise"],
"requires_approval": True,
},
DataClassification.CONFIDENTIAL: {
"allowed_providers": ["private-vpc-model"],
"requires_approval": True,
"requires_audit": True,
},
DataClassification.PII: {
"allowed_providers": ["private-vpc-model"],
"requires_approval": True,
"requires_audit": True,
"requires_encryption": True,
}
}
def check_policy(self, classification: str, provider: str) -> Dict[str, Any]:
"""Check if request complies with policy"""
if classification not in self.rules:
return {"allowed": False, "reason": "Unknown classification"}
rule = self.rules[classification]
if provider not in rule["allowed_providers"]:
return {
"allowed": False,
"reason": f"Provider {provider} not allowed for {classification} data"
}
return {
"allowed": True,
"requires_approval": rule.get("requires_approval", False),
"requires_audit": rule.get("requires_audit", False),
"requires_encryption": rule.get("requires_encryption", False),
}
# Audit Logger
class AuditLogger:
"""Logs all AI interactions for compliance and incident response"""
def log_request(
self,
user_id: str,
classification: str,
provider: str,
input_size: int,
output_size: int,
timestamp: datetime,
policy_result: Dict[str, Any],
):
"""Log AI request to audit system"""
log_entry = {
"timestamp": timestamp.isoformat(),
"user_id": user_id,
"data_classification": classification,
"provider": provider,
"input_size_bytes": input_size,
"output_size_bytes": output_size,
"policy_allowed": policy_result["allowed"],
"policy_reason": policy_result.get("reason"),
}
# In production: write to secure audit log (e.g., BigQuery, CloudWatch)
logging.info(f"AI_AUDIT: {log_entry}")
# Example: Write to database or SIEM
# audit_db.insert(log_entry)
# Main Gateway Service
app = FastAPI(title="AI Gateway", version="1.0.0")
dlp_service = DLPService()
policy_engine = PolicyEngine()
audit_logger = AuditLogger()
class AIRequest(BaseModel):
content: str
provider: str = "openai"
user_id: str
class AIResponse(BaseModel):
result: str
classification: str
redacted: bool
policy_compliant: bool
@app.post("/ai/generate", response_model=AIResponse)
async def generate_ai(request: AIRequest):
"""Secure AI generation endpoint"""
# Step 1: Classify data
classification = dlp_service.classify_data(request.content)
# Step 2: Check policy
policy_result = policy_engine.check_policy(classification, request.provider)
if not policy_result["allowed"]:
raise HTTPException(
status_code=403,
detail=f"Policy violation: {policy_result['reason']}"
)
# Step 3: Redact if needed
redacted_content = request.content
redacted = False
if classification in [DataClassification.PII, DataClassification.CONFIDENTIAL]:
redacted_content = dlp_service.redact_sensitive(request.content, classification)
redacted = redacted_content != request.content
# Step 4: Route to appropriate provider
# In production: call actual AI provider API
result = f"[AI Response for {classification} data]"
# Step 5: Audit log
audit_logger.log_request(
user_id=request.user_id,
classification=classification,
provider=request.provider,
input_size=len(request.content.encode()),
output_size=len(result.encode()),
timestamp=datetime.utcnow(),
policy_result=policy_result,
)
return AIResponse(
result=result,
classification=classification,
redacted=redacted,
policy_compliant=True,
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Data Classification Automation
Example: Automated Classification Service
"""
Automated data classification using ML and pattern matching
"""
import re
from typing import List, Tuple
from dataclasses import dataclass
@dataclass
class ClassificationResult:
level: str
confidence: float
matched_patterns: List[str]
recommendations: List[str]
class AutoClassifier:
"""Automatically classify data sensitivity"""
def __init__(self):
self.pii_patterns = {
"ssn": r'\b\d{3}-\d{2}-\d{4}\b',
"credit_card": r'\b\d{4}[\s-]?\d{4}[\s-]?\d{4}[\s-]?\d{4}\b',
"email": r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
"phone": r'\b\d{3}[-.]?\d{3}[-.]?\d{4}\b',
"ip_address": r'\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b',
}
self.confidential_keywords = [
"proprietary", "confidential", "internal use only",
"trade secret", "nda", "non-disclosure"
]
self.code_indicators = [
"def ", "function ", "class ", "import ", "package ",
"SELECT", "INSERT", "CREATE TABLE"
]
def classify(self, content: str) -> ClassificationResult:
"""Classify content and return result with confidence"""
matched = []
recommendations = []
# Check for PII
pii_found = False
for name, pattern in self.pii_patterns.items():
if re.search(pattern, content, re.IGNORECASE):
matched.append(f"PII: {name}")
pii_found = True
if pii_found:
return ClassificationResult(
level=DataClassification.PII,
confidence=0.95,
matched_patterns=matched,
recommendations=[
"Never send to public AI models",
"Use private VPC model only",
"Require encryption in transit and at rest"
]
)
# Check for confidential indicators
confidential_found = any(
keyword in content.lower() for keyword in self.confidential_keywords
)
# Check for code
code_found = any(
indicator in content for indicator in self.code_indicators
)
if confidential_found or code_found:
return ClassificationResult(
level=DataClassification.CONFIDENTIAL,
confidence=0.85,
matched_patterns=matched + (["confidential_keywords"] if confidential_found else []) + (["code_indicators"] if code_found else []),
recommendations=[
"Use private model or approved enterprise provider",
"Require manager approval",
"Enable audit logging"
]
)
# Default to internal
return ClassificationResult(
level=DataClassification.INTERNAL,
confidence=0.70,
matched_patterns=matched,
recommendations=[
"Use approved enterprise AI providers",
"Review output before use"
]
)
Kill Switch Implementation
Example: Environment-Based Kill Switch
"""
Kill switch for disabling AI features instantly
"""
import os
from typing import Dict, Any, Callable, Optional
from enum import Enum
class KillSwitchStatus(Enum):
ENABLED = "enabled"
DISABLED = "disabled"
DEGRADED = "degraded" # Limited functionality
class KillSwitch:
"""Centralized kill switch for AI services"""
def __init__(self):
self.status = self._read_status()
self.reason = os.getenv("AI_KILL_SWITCH_REASON", "")
def _read_status(self) -> KillSwitchStatus:
"""Read kill switch status from environment"""
status_str = os.getenv("AI_ENABLED", "true").lower()
if status_str == "false" or status_str == "disabled":
return KillSwitchStatus.DISABLED
elif status_str == "degraded":
return KillSwitchStatus.DEGRADED
else:
return KillSwitchStatus.ENABLED
def is_enabled(self) -> bool:
"""Check if AI is enabled"""
return self.status == KillSwitchStatus.ENABLED
def get_fallback_response(self, service_type: str) -> Dict[str, Any]:
"""Get deterministic fallback when AI is disabled"""
fallbacks = {
"code": {
"suggestions": [],
"message": "AI code assistance is currently disabled. Please contact IT support.",
},
"document": {
"summary": "",
"message": "AI document processing is currently disabled.",
},
"chat": {
"response": "AI chat is currently unavailable. Please try again later.",
}
}
return fallbacks.get(service_type, {"message": "AI service unavailable"})
def with_kill_switch(
self,
ai_function: Callable,
service_type: str,
*args,
**kwargs
) -> Dict[str, Any]:
"""Execute AI function with kill switch protection"""
if not self.is_enabled():
return {
"result": self.get_fallback_response(service_type),
"ai_enabled": False,
"status": "fallback",
"reason": self.reason or "Kill switch activated",
}
try:
result = ai_function(*args, **kwargs)
return {
"result": result,
"ai_enabled": True,
"status": "success",
}
except Exception as e:
# On error, fall back gracefully
return {
"result": self.get_fallback_response(service_type),
"ai_enabled": True,
"status": "error",
"error": str(e),
}
Governance and Policy Framework
AI Risk Lifecycle

Policy Template: AI Usage Policy
Sample AI Usage Policy Structure:
AI Usage Policy
1. Scope
This policy applies to all employees, contractors, and third parties using AI tools for company business.
2. Data Classification
Public Data
- Definition: Marketing materials, public documentation, non-sensitive content
- Allowed: Public AI tools (ChatGPT, Claude, etc.)
- Requirements: Basic review of outputs
Internal Non-Sensitive
- Definition: Internal process docs, non-confidential policies
- Allowed: Approved enterprise AI providers only
- Requirements: Manager approval, audit logging
Confidential Data
- Definition: Source code, architecture, contracts, strategy
- Allowed: Private VPC models only
- Requirements: CISO approval, encryption, full audit trail
PII / Highly Sensitive
- Definition: Customer data, HR data, health data, financial records
- Allowed: Private VPC models with data processing agreements
- Requirements: CISO + Legal approval, encryption, anonymization, full audit
3. Prohibited Uses
- Never paste PII into public AI tools
- Never paste proprietary code into public AI tools
- Never use personal AI accounts for company data
- Never use unapproved browser extensions or plugins
4. Approved Tools
Public Tools (Public Data Only)
- ChatGPT (with company account)
- Claude (with company account)
- Google Gemini (with company account)
Enterprise Tools (Internal/Confidential)
- OpenAI Enterprise
- Anthropic Enterprise
- Microsoft Copilot (with data residency)
Private Tools (PII/Confidential)
- Private VPC-hosted models
- On-premise AI infrastructure
5. Incident Response
If you suspect data has been leaked:
- Immediately stop using the AI tool
- Report to security@company.com
- Document what data was shared
- Do not attempt to delete or cover up
6. Training Requirements
All employees must complete:
- Annual AI security training
- Data classification training
- Incident reporting procedures
7. Enforcement
Violations may result in:
- Disciplinary action
- Termination for willful violations
- Legal action for data breaches
Ownership and Accountability
RACI Matrix for AI Governance:
| Activity | CISO | Legal | Engineering | Product | Employees |
|---|---|---|---|---|---|
| Data Classification | A | C | R | I | I |
| Policy Creation | R | A | C | C | I |
| Technical Controls | A | I | R | C | I |
| Training | C | I | I | C | R |
| Incident Response | R | A | C | I | R |
| Monitoring | A | I | R | C | I |
Legend:
- R = Responsible (does the work)
- A = Accountable (owns the outcome)
- C = Consulted (provides input)
- I = Informed (kept in the loop)
Case Studies and Real-World Examples
Case Study 1: Code Leakage Incident
Scenario: A software company’s engineers were using ChatGPT to debug code. Over several months, proprietary algorithms and architecture details were pasted into the tool.
Impact:
- Competitive advantage lost
- Potential IP violation
- Customer trust damaged
Root Cause:
- No policy on AI usage
- No technical controls
- No monitoring
Solution Implemented:
- Immediate: Blocked public AI tools, required VPN for approved tools
- Short-term: Implemented AI gateway with DLP
- Long-term: Private code analysis tools, training program
Lessons:
- Code is always confidential
- Technical controls beat policy alone
- Monitor before you have an incident
Case Study 2: Healthcare PII Exposure
Scenario: A healthcare organization’s staff used AI tools to summarize patient notes. Patient names, conditions, and treatment plans were exposed.
Impact:
- HIPAA violation
- Regulatory fines
- Patient lawsuits
Root Cause:
- PII not properly classified
- No redaction before AI processing
- Staff not trained on data sensitivity
Solution Implemented:
- Immediate: Shut down all AI tools, incident response
- Short-term: Implemented PII detection and redaction
- Long-term: Private healthcare AI model, comprehensive training
Lessons:
- Healthcare data requires special handling
- Automated redaction is essential
- Training must be role-specific
Case Study 3: Successful Implementation
Scenario: A financial services company wanted to use AI for customer support but had strict regulatory requirements.
Approach:
- Classified all customer data as PII
- Implemented private VPC-hosted model
- Added full audit logging
- Trained all support staff
- Started with low-risk use cases
Results:
- Zero data leaks in 12 months
- 30% reduction in support ticket resolution time
- Regulatory approval maintained
Key Success Factors:
- Started with classification
- Technical controls from day one
- Continuous monitoring and improvement
What I Learned From Cancer Models That Applies to Corporate AI
Working on predictive models for cancer detection taught me a few non-negotiable rules:
- The cost of a wrong decision matters more than the beauty of the model.
- You can’t separate model performance from data governance.
- You must be able to explain and defend your approach when it matters most.
I see too many companies obsess over model performance and UX while ignoring the basics:
- Where is the data coming from?
- Who controls it end-to-end?
- What happens if the worst-case scenario actually occurs?
When you’re dealing with people’s lives or livelihoods, “we were experimenting” is not an excuse. It’s a confession.
The Parallels
| Research Context | Corporate AI Context |
|---|---|
| Patient data privacy | Customer PII protection |
| Model explainability | Regulatory compliance |
| Error cost (misdiagnosis) | Error cost (data breach) |
| Peer review | Security audit |
| IRB approval | CISO/Legal approval |
| Reproducibility | Audit trails |
Conclusion: AI with Discipline
Three Clear Takeaways for Leaders and Teams
If you’re serious about AI and don’t want to be the next cautionary case study, treat these as the bare minimum:
1. Ban Confidential and PII Data from Public AI Tools - and Enforce It Technically
Policies without controls are theatre. You need:
- Automated data classification
- Technical controls (gateway, DLP, routing)
- Monitoring and alerting
- Incident response procedures
2. Use a Risk-Based Approach to AI Features
Don’t treat a marketing chatbot and an AI credit scorer as the same. They are not.
- Classify use cases by impact and sensitivity
- Apply appropriate controls for each quadrant
- Start with low-risk, high-value use cases
- Build capability before tackling high-risk scenarios
3. Measure Success with Safety and Trust Included
Track not only adoption and revenue, but also:
- Incidents and near misses
- Policy violations
- User trust metrics
- Cost of controls vs. cost of incidents
If those metrics are invisible, your AI programme is fundamentally incomplete.
The Choice
AI is not going away. The question is whether we force it to grow up - or we let greed and fear drive us into predictable disasters.
The choice is not “AI or safety”. The serious choice is:
AI with discipline, or AI with collateral damage.
Author: Dr. Atabak Kheirkhah
Date: November 30, 2025
Contact: atabakkheirkhah@gmail.com
This is a personal blog. The views, thoughts, and opinions expressed here are my own and do not represent, reflect, or constitute the views, policies, or positions of any employer, university, client, or organization I am associated with or have been associated with.